رمزنگاری کتابی با پایتون

رمزنگاری کتابی
امروزه کتاب ها یکی از دردسترس ترین و پراستفاده ترین چیزای زندگی هممون هستند . چه آدم کتابخونی باشیم یا نه کاملا برعکس ، فرقی نمیکنه در نهایت ما همیشه با کتاب ها سروکار داریم . جالبه بدونید که با استفاده از همین کتاب ها میشه اطلاعاتمون رو رمز کنیم و به بقیه انتقال بدیم . احتمالا روش های مختلفی برای اینکار وجود داره ولی یه نوع الگوریتم رمزنگاری هست به نام رمزنگاری کتابی (Book Cipher) که با استفاده از اون متون خودمون رو با بهره گیری از کتاب ها ، رمز میکنیم .
تو این روش ، هر دو طرف یعنی گیرنده و فرستنده باید سر یک کتاب دقیقا یکسان توافق کنند . یا شایدم سر یک صفحه خاص از یک کتاب خاص . و با استفاده از این توافقشونه که میتونن داده ها رو رمزنگذاری یا رمزگشایی کنن . به عبارتی در واقع اینجا کتاب نقش کلید رو برای ما داره. با این کلید میتونیم رمزگذاری و رمزگشایی کنیم .
رمزنگاری کتابی عموما به دو روش اصلی انجام میشه : مبتنی بر لغت ، مبتنی بر حرف .
رمزنگاری کتابی مبتنی بر لغت
روش کار در این مورد بسیار سادست . در این الگوریتم ما میایم هر لغت داخل متن اولیه مون (که میخوایم رمز بشه) رو با جایگاه اون لغت در یک کتاب خاص جایگزین میکنیم . فرض کنید من میخوام متن “سلام دوست من” رو رمزنگاری کنم و برای اینکار کتاب X رو انتخاب کردم . جمله من از سه کلمه سلام ، دوست و من تشکیل شده . ابتدا میام کلمه سلام رو داخل کتاب X پیدا میکنم . مثلا میبینم کلمه سلام چهارمین کلمه خط چهاردهم صفحه 54 کتاب X هستش . بنابراین به جای سلام در متن اولیه مینویسم :
45-14-4
این عبارت نشون دهنده آدرس کلمه مورد نظره . از سمت چپ ابتدا شماره صفحه ، سپس شماره خط و نهایتا شماره کلمه داخل آن خط رو مشخص کردیم . به همین روش برای کلمات دوست و من هم همینکارو میکنیم .
نهایتا فرض کنید متن سلام دوست من به چنین چیزی تبدیل میشه :
45-14-4
102-3-4
56-1-6
این شد متن رمزنگاری شده . برای رمزگشایی کافیه این جایگاه ها رو با کلمات داخل کتاب X جایگزین کنیم .
نکته ای که هست اینه که هر دو طرف ارتباط دقیقا باید سر یک کتاب یکسان و حتی یک ویرایش یکسان از کتاب توافق کرده باشن وگرنه عمل رمزگذاری و رمزگشایی تطابق نخواهند داشت .
پیاده سازی رمزنگاری کتابی مبتنی بر لغت در پایتون
فرض کنیم کتاب های ما یک سری pdf هستند و میخوایم با این ها رمزنگاری کتابی رو پیاده سازی کنیم . میتونیم به سادگی اسکریپتی در پایتون بنویسیم که اینکارو برامون انجام بده . برای کار با pdf و خواندن متن صفحات آن از کتابخونه PyPDF2 استفاده میکنیم . برای نصب این کتابخونه میتونیم از ابزار pip استفاده کنیم :
pip install PyPDF2
کار با PyPDF2 خیلی راحت و سر راسته . تنها کاری که ما با این کتابخونه داریم خوندن متون داخل pdf هست . این کتابخونه کلاسی داره به اسم PdfReader که شامل توابعی هست که میتونیم متون داخل pdf رو استخراج کنیم . تکه کد زیر یه نمونه برای استخراج متن از صفحه خاصی از یک pdf هست :
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf") # open example.pdf
page1 = reader.pages[0] # get page 1
print(page1.extract_text()) # extract text from page 1
در خط اول کلاس PdfReader از کتابخونه رو import کردیم .
در خط 2 یک شیء از کلاس PdfReader درست کردیم و گفتیم که فایل example.pdf رو برامون باز کنه .
سپس در خط 3 صفحه اول از کتابی که در خط قبل باز کردیم رو گرفتیم و در متغییر page1 ذخیره کردیم .
نهایتا در خط آخر متن داخل صفحه اول رو به وسیله تابع extract_text استخراج کردیم و روی صفحه چاپ کردیم .
این یک معرفی کلی از کتابخونه PyPDF2 بود که برای کار ما کافیه . برای مطالعه بیشتر در مورد این کتابخونه به Documentation رسمی کتابخونه مراجعه کنید .
اسکریپت رمزگذار کتابی مبتنی بر لغت :
from PyPDF2 import PdfReader
def encryptWord(word):
for page_index in range(number_of_pages):
page = reader.pages[page_index] # get page
page_text = page.extract_text().lower()
if word in page_text:
page_lines = page_text.split("\n") # list of lines in the page
number_of_lines = len(page_lines)
for line_index in range(number_of_lines):
line = page_lines[line_index] # get line
words = line.split(" ")
if word in words :
word_index = words.index(word)
return "{}-{}-{}".format(page_index+1 , line_index+1 , word_index+1)
text = input("Text to encrypt : ")
key = input("Book : ")
text = text.lower()
reader = PdfReader(key) # open pdf book
number_of_pages = len(reader.pages)
for word in text.split(" "):
print(encryptWord(word) , end =",")
از خط 19 تا 27 رو ملاحظه کنید . ابتدا متنی که میخوایم رمز کنیم رو گرفتیم و داخل متغییر text ذخیره کردیم .
در خط بعد کتابی که میخوایم به وسیله اون رمز کنیم رو گرفتیم و در key ذخیره کردیم . در خط بعد اومدیم تمام حروف داخل text رو به حروف کوچیک انگلیسی تبدیل کردیم .
در خط 23 کتاب مورد نظر رو با کلاس PdfReader باز کردیم . در خط 24 هم که تعداد صفحات کتاب رو بدست آوردیم و ریختیم داخل متغییر number_of_pages .
بعد از اون یک حلقه for روی تک تک کلمات داخل text زدیم و به ازای هر کلمه ، تابع encryptWord رو فراخونی کردیم و نتیجشو چاپ کردیم . این تابع کارش اینه که یک کلمه رو بگیره و با استفاده از کتاب اون رو رمزکنه .
اما بیاید نگاهی به تابع encryptWord بندازیم :
def encryptWord(word):
for page_index in range(number_of_pages):
page = reader.pages[page_index] # get page
page_text = page.extract_text().lower()
if word in page_text:
page_lines = page_text.split("\n") # list of lines in the page
number_of_lines = len(page_lines)
for line_index in range(number_of_lines):
line = page_lines[line_index] # get line
words = line.split(" ")
if word in words :
word_index = words.index(word)
return "{}-{}-{}".format(page_index+1 , line_index+1 , word_index+1)
در ابتدا یک for زدیم روی تمام صفحات کتاب . سپس متن اون صفحه رو استخراج کردیم و داخل متغییر page_text ذخیره کردیم . بعد اومدیم چک کردیم که آیا کلمه مورد نظر ما (word) داخل اون صفحه هست یا نه . اگه نباشه داخلش که باید بریم صفحه بعدیو چک کنیم . اگر داخلش بود باید آدرس اون کلمه رو در بیاریم . ابتدا یه لیستی از تمام خطوط داخل اون صفحه درست کردیم و ریختیم داخل متغییر page_lines . سپس تعداد خطوط داخل اون صفحه رو بدست آوردیم و در متغییر number_of_lines ذخیره کردیم .
حالا یک for روی خطوط صفحه انجام میدیم و به ازای هر خط در صفحه ، یه لیستی از لغات داخل اون خط درست میکنیم و اسمشو قرار میدیم words . حالا چک میکنیم اگه کلمه مورد نظر ما داخل اون لیست کلمات بود ، جایگاه اون کلمه رو داخل کتاب به عنوان خروجی تابع بر میگردونیم .
برای تست کردن من از کتاب C++ Language Tutorial استفاده میکنم که میتونید از لینک زیر دانلودش کنید :
برای تست ، من متن how to create a c++ program رو وارد میکنم و بهش میگم با کتابی که بالا معرفی شد رمز کنه :
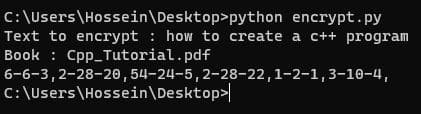
همینطور که میبینید رمزنگذاری به درستی انجام شد و متن رمزشده به من برگشت .
حالا بریم اسکریپتی بنویسیم که بتونه عمل رمزگشایی رو انجام بده :
from PyPDF2 import PdfReader
def wordDecrypt(word):
word = word.split("-")
page_index = int(word[0])
line_index = int(word[1])
word_index = int(word[2])
page = reader.pages[page_index-1]
page_data = page.extract_text()
line = page_data.split("\n")[line_index-1]
word = line.split(" ")[word_index-1]
return word
text = input("Text to decrypt : ")
key = input("Book : ")
text = text.lower()
reader = PdfReader(key) # open pdf book
for word in text.split(","):
if word == "" : break
print (wordDecrypt(word) , end = " ")
این اسکریپت هم دقیقا با همون قبلی تطابق داره . اونو متوجه شده باشید اینو به راحتی متوجه میشید و نیازی به توضیح نیست .
این اسکریپت رو با متن رمزشده قبلی تست میکنیم که ببینیم درست رمزگشایی میکنه یا نه :

رمزنگاری کتابی مبتنی بر حرف
در روش مبتنی بر کلمه ما میومدیم سر یک کتاب یکسان توافق میکردیم و هر کلمه داخل متن اولیه رو با آدرس اون داخل کتاب جایگزین میکردیم اما روش مبتنی بر لغت کمی تفاوت داره .
در روش مبتنی بر حرف ما میایم سر یک کتاب یکسان و همچنین یک صفحه خاص از همان کتاب توافق میکنیم. سپس تک تک حروف داخل متن اولیه رو در صفحه انتخاب شده پیدا میکنیم و با شماره اون حرف داخل صفحه جایگزین میکنیم .
فرض کنید ما متن “چطوری پسر” رو داریم . همچنین توافق ما سر صفحه 56 کتاب X هستش . در عبارت چطوری پسر ، اولین حرف چ هستش . مثلا میبینیم چ هشتادو سومین حرف داخل صفحه 56 کتابه . پس به جای حرف چ مینویسیم 56 . همینجوری تمام حروف رو در میاریم و مینویسیم تا نهایتا متنمون رمز میشه . برای راحتی بیشتر عدد حروف رو در متن رمزشده با فاصله از هم جدا میکنیم و بین هر کلمه یک علامت ویرگول (,) قرار میدیم .
مثلا عبارت زیر رو ببینید :
89 7 6 21, 25 30 65 85
این عبارت از دو کلمه تشکیل شده چون یک ویرگول بینشونه . کلمه اول از سمت چپ 4 تا حرف داره و عدد هر حرف رو هم نوشتیم . کلمه دوم هم چهارتا حرف داره . اگه بریم تو اون صفحه مورد توافق و این حروف رو پیدا کنیم و جایگذاری کنیم متن اولیه بدست میاد .
پیاده سازی رمزنگاری کتابی مبتنی بر حرف در پایتون
اتفاقا پیاده سازی این روش ساده تر از روش مبتنی بر کلمه هست . کمی تغییرات توی اسکریپت رمزگذار قبلی بوجود آوردیم :
from PyPDF2 import PdfReader
def encryptLetter(letter , page_number):
page = reader.pages[page_number-1]
page_text = page.extract_text()
letter_index = page_text.index(letter)
return letter_index+1
text = input("Text to encrypt : ")
key = input("Book : ")
page_number = int(input("Page number : "))
text = text.lower()
reader = PdfReader(key) # open pdf book
for word in text.split(" "):
for letter in word:
print(encryptLetter(letter , page_number) , end =" ")
print ("," , end = '')
از خط 10 تا 21 رو دقت کنید . مثل قبل متن و اسم کتاب رو میگیریم . این بار شماره صفحه رو هم گرفتیم و در متغییر page_number ذخیره کردیم .
سپس در خط 18 یک for روی کلمات متن اولیه اجرا کردیم و همچنین داخل اون یک for روی تک تک حروف اون کلمه هم اجرا کردیم . به ازای هر حرف ، تابع encryptLetter رو فراخونی کردیم و خود حرف و شماره صفحه رو بهش به عنوان ورودی پاس دادیم . از اسم تابع مشخصه که یک حرف رو میگیره و شماره اون حرف توی صفحه مورد نظر رو بر میگردونه (حرف رو رمز میکنه) .
اما بریم سراغ بررسی تابع ساده encryptLetter :
def encryptLetter(letter , page_number):
page = reader.pages[page_number-1]
page_text = page.extract_text()
letter_index = page_text.index(letter)
return letter_index+1
ابتدا اون صفحه مورد نظر رو گرفتیم و در page ذخیره کردیم . سپس متن داخل صفحه رو استخراج کردیم و ریختیم داخل page_text . بعد از اون هم اومدیم اندیس حرف مورد نظر رو داخل متن صفحه پیدا کردیم و ریختیم داخل letter_index . نهایتا اون اندیس رو به عنوان خروجی برگردوندیم . دقت کنید دلیل اینکه یکی بهش اضافه کردیم اینه که اندیس های پایتون از صفر شروع میشن ولی ما تمایل داریم از یک بشماریم .
این اسکریپت رو هم تست میکنیم . همون متن قبلی رو با همون کتاب قبلی روی صفحه 74 بهش میدیم ببینیم چی برامون تولید میکنه :

خب ظاهرا درست کار میکنه . بریم سراغ اسکریپت رمزگشا :
from PyPDF2 import PdfReader
def decryptLetter(letter , page_number):
page = reader.pages[page_number-1]
page_text = page.extract_text()
letter_index = int(letter) - 1
return page_text[letter_index]
text = input("Text to decrypt : ")
key = input("Book : ")
page_number = int(input("Page number : "))
text = text.lower()
reader = PdfReader(key) # open pdf book
for word in text.split(","):
if word == "" : break
for letter in word.split(" "):
if letter == "" : break
print(decryptLetter(letter , page_number) , end ="")
print (" " , end = '')
اینجا باز همون ساختار قبلی رو داریم با این تفاوت که تابع encryptLetter تبدیل شده به decryptLetter .
به عنوان ورودی رمزشده حرف مورد نظر رو به همراه شماره صفحه میگیره و اون حرف رو تو اون صفحه برمیگردونه .
نیازی به توضیح بیشتر نیست کاملا واضحه چه خبره .
ببنیم میتونه عبارتی که اسکریپت رمزگذاری تولید کرد رو رمزگشایی کنه یا نه :

بسیار هم عالی 🙂
جمع بندی
دقت کنید از هرکدوم از روش ها چه مبتنی بر لغت و چه مبتنی بر حرف که استفاده میکنید ، حتما باید اون کلمه مورد نظر داخل کتاب باشه یا اون حرف مورد نظر داخل انتخاب شده وجود داشته باشه وگرنه با مشکل مواجه میشیم .
یکی از بهترین کتاب ها برای انتخاب به عنوان کلید دیکشنری ها یا لغت نامه ها هستند . چون شامل طیف وسیعی از کلمات هستند و خب این باعث میشه برای این نوع رمزنگاری بسیار مناسب باشن .
امیدوارم که لذت برده باشید … تا آموزش های بعدی بدرود … 🙂
منابع
Book Ciphers
https://derekbruff.org/blogs/fywscrypto/historical-crypto/whats-in-a-book-a-brief-history-of-book-ciphers/
این آموزش متعلق به بخش رمزنگاری است
برای مشاهده تمام آموزش های رمزنگاری وبسایت مسترپایتون به بخش رمزنگاری مراجعه کنید

علاقه مند به دنیای کامپیوتر ها ...